(번역) 2019년 7월 2일 Cloudflare 장애 보고서
Contents
2019년 7월 2일에 발생한 Cloudflare 서버 장애 사태에 대해서 Cloudflare의 CTO인 John Graham-Cumming이 사건 개요와 대처 등을 정리한 글입니다. Cloudflare라는 대규모 조직에서 어떤 식으로 문제가 발생하고, 그것을 어떻게 대처하는지를 알 수 있는 글입니다.
정규표현식에 대한 기술적인 분석을 담고 있는 Appendix는 중요하지 않다고 판단되어 빠져있습니다. 궁금하신 분들은 원문을 읽어보는 것을 추천드립니다.
약 9년 전, Cloudflare가 아주 작은 회사였고, 제가 임원이 아니라 Cloudflare를 사용하는 고객이었을 때의 일입니다. 어느 날 제 홈페이지인 jgc.org에 연결된 DNS 서비스가 제대로 동작하지 않는다는 알림을 받았습니다. Cloudflare에서 Protocol Buffers를 사용하는 방식을 바꿨고 이것이 DNS를 망가트린 것이었죠.
그래서 저는 Matthew Prince1에게 바로 “Where’s my dns?“라는 제목의 메일을 보냈습니다. 그러자 그는 곧바로 아주 길고 상세한 기술적인 내용이 담긴 답변을 보내왔습니다 (전체 메일 내용은 여기에서 볼 수 있음). 그래서 저는 다음과 같은 답신을 보냈습니다.
| |
그리고 그는 이렇게 답변했습니다.
| |
그래서 오늘, 그 당시보다 훨씬 커진 Cloudflare의 임원으로서, 얼마 전 발생한 문제에 대해서 우리가 어떠한 실수를 했고, 그것이 어떠한 영향을 주었고, 그래서 우리가 어떻게 대처했는지를 투명하게 말씀드리려고 합니다.
7월 2일에 발생한 사건
7월 2일, 우리는 WAF(Web Application Firewall) 관리 규칙을 새로 배포했고, 이 새로운 규칙이 Cloudflare 네트워크로 들어오는 HTTP/HTTPS 트래픽을 처리하는 모든 CPU를 고갈시켰습니다. 새로운 취약점과 위협에 대응하기 위해서 Cloudflare의 WAF 관리 규칙은 지속적으로 업데이트 됩니다. 예를 들어, 5월에는 SharePoint 취약점을 막는 규칙을 빠르게 배포했었습니다. 이러한 규칙들을 빠르게 전세계의 서버에 배포하는 것은 우리의 WAF가 매우 중요시 생각하는 기능 중 하나입니다.
불행하게도, 지난 화요일의 업데이트에는 매우 많은 백트래킹이 발생하는 정규표현식이 포함되어 있었고, 이 때문에 HTTP/HTTPS 트래픽을 처리해야 하는 CPU가 모두 고갈되어 버렸습니다. 이것이 Cloudflare의 프록시, CDN, WAF 기능을 모두 마비시키는 결과를 초래했습니다. 아래 그래프는 HTTP/HTTPS 트래픽을 처리하기 위하여 할당된 Cloudflare 네트워크 상의 CPU의 사용률이 100%에 근접하는 모습을 보여줍니다.
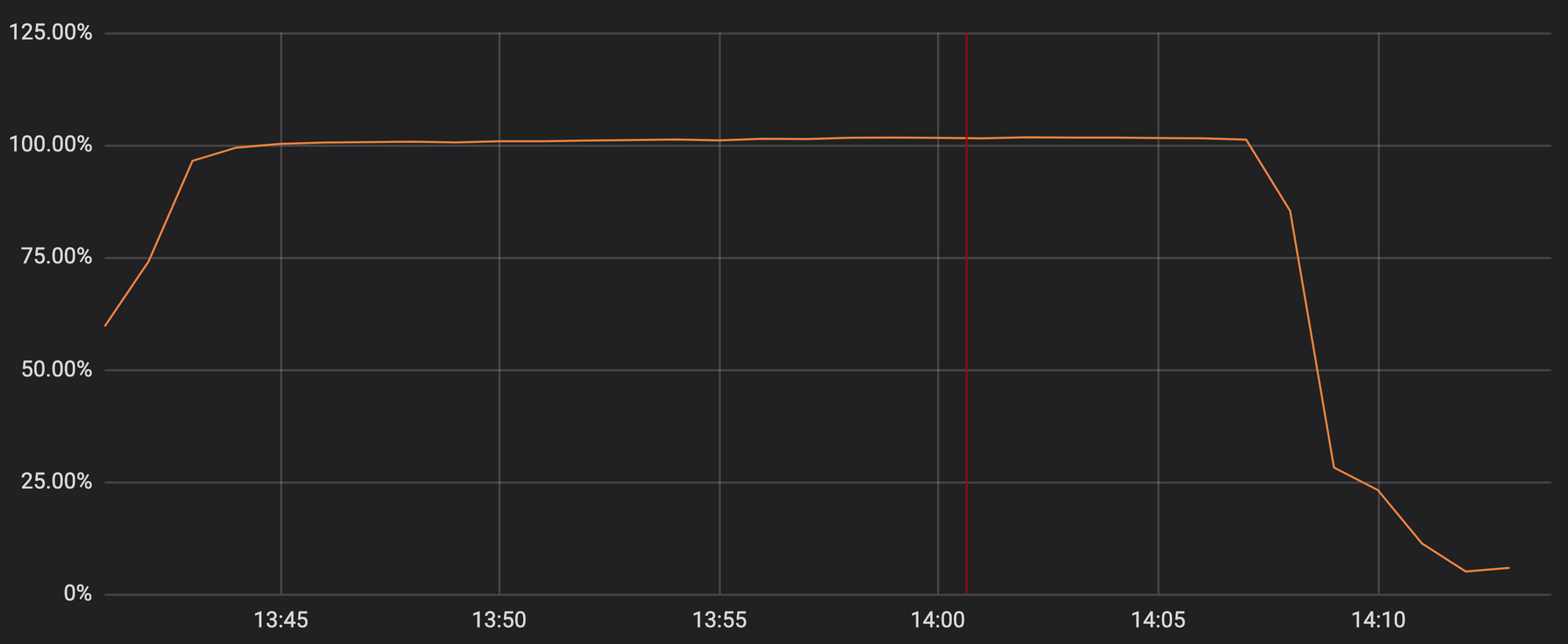
이 때문에 Cloudflare의 고객들 (그리고 고객들의 고객들)이 Cloudflare를 사용하는 도메인에 접속할 때 502 에러 페이지를 보게 되었습니다. 앞단의 Cloudflare 웹 서버에는 여전히 사용가능한 CPU 코어가 남아있어서 502 에러 메세지는 생성되었지만, HTTP/HTTPS 트래픽을 처리하는 프로세스에는 도달하지 못한 것입니다.
CPU 고갈 사태는 단 하나의 WAF 규칙 때문에 발생했습니다. 매우 비효율적으로 작성된 정규표현식이 수많은 백트래킹 과정을 만들어냈기 때문입니다. 문제가 되는 정규표현식은 아래와 같습니다.
| |
이 정규표현식 자체에 관심이 있는 분들이 많을 거라고 생각합니다만, 어떻게 Cloudflare의 서비스가 27분 동안 다운되었는가는 단순히 “정규표현식을 잘못 썼다"라는 것보다는 더 복잡합니다. 그래서 빠르게 대처하는 글을 올리는 대신, 일련의 사건을 짚어보는 글을 오랜 시간을 들여 작성하였습니다. 만약 정규표현식의 백트래킹에 대해서 궁금하시다면, appendix 부분(번역하지 않음)을 참고하시길 바랍니다.
무슨 일이 일어났는가
사건의 발생 과정을 순서대로 짚어봅시다. 아래의 모든 시간은 UTC 기준입니다.
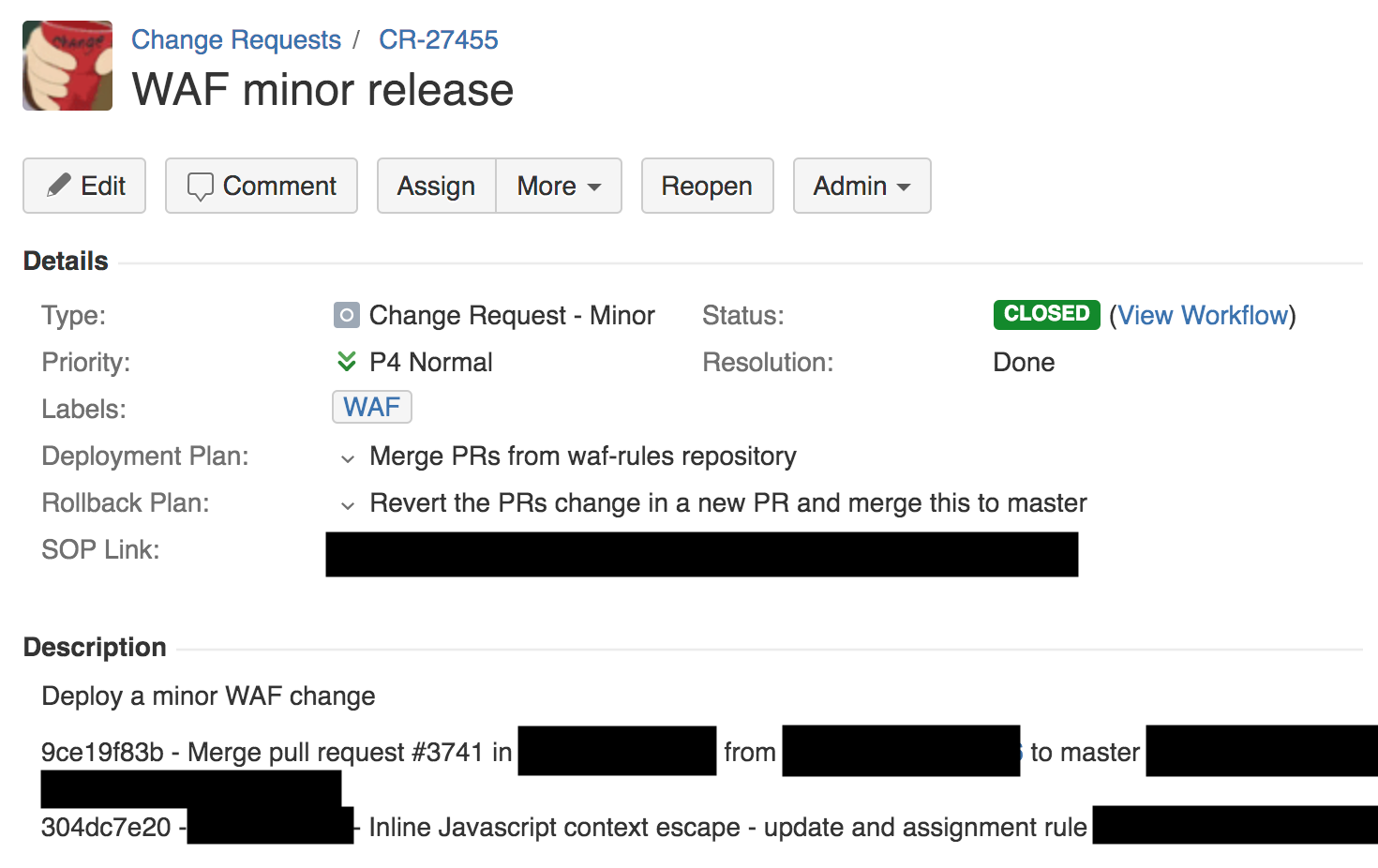
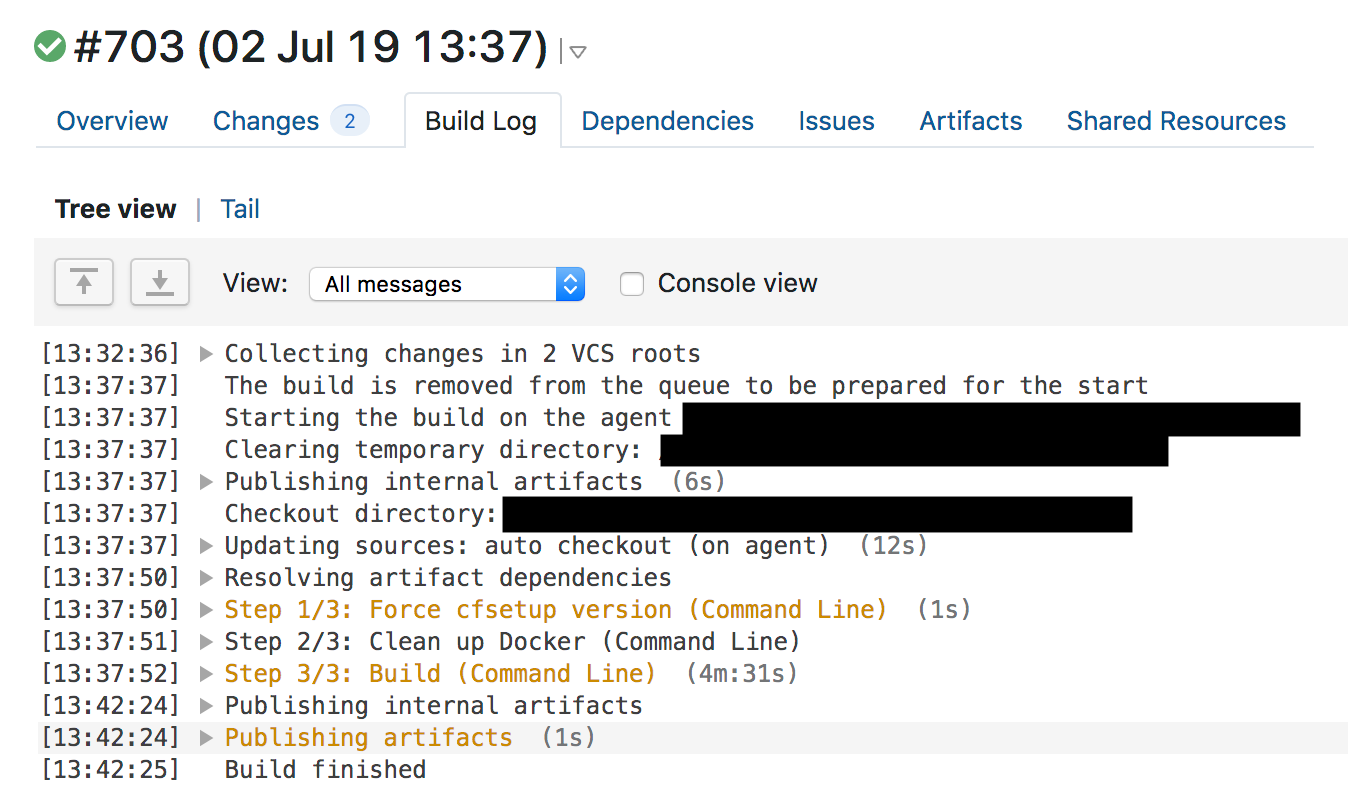
13시 42분에 방화벽 팀의 엔지니어가 XSS 감지를 위한 규칙을 배포했습니다. 이는 Change Request 티켓을 생성합니다. 우리는 Jira를 사용하여 이러한 티켓을 관리합니다. 아래 스크린샷을 참고해주세요.
3분 뒤, PagerDuty에서 WAF에 문제가 있음을 알리는 첫번째 경고가 발생했습니다. 이는 Cloudflare 외부에서 WAF가 제대로 동작하는지 확인하기 위하여 수행하는 종합 테스트의 하나입니다 (이러한 테스트가 수백 개 존재합니다.). 이후 곧바로 Cloudflare의 종단간 통신 테스트가 실패했다는 경고와, 글로벌하게 트래픽이 드랍되어 502 에러가 발생하고 있다는 경고가 발생했습니다. 전세계 각 도시의 PoPs(points-of-presence)로부터도 CPU 고갈에 대한 수많은 보고가 왔습니다.


위와 같은 경고들이 제 시계에 표시되는 것을 보고, 저는 진행 중이던 미팅에서 빠져나와, 대응팀에게서 80%에 해당하는 트래픽이 드랍되고 있다는 사실을 보고받았습니다. 처음에는 이 장애 사태가 지금까지 본 적 없는 새로운 형태의 공격이라고 생각했습니다.

Cloudflare의 SRE(Site Reliability Engineering, 사이트 신뢰성 엔지니어링) 팀은 전 세계에 퍼져서 24시간 서비스를 관리하고 안정화합니다. SRE 팀에서 보내는 경고는 대부분 특정 지역에 한정된 이슈가 발생하고 있다는 점을 알려주고, 이러한 이슈는 매일 흔히 발생합니다. 그러나 위와 같은 Global Traffic Drop 경고는 매우 심각한 사태가 일어났다는 것을 알려줍니다. SRE 팀은 곧바로 P02 레벨 사태를 선언하고 이 문제를 시스템 엔지니어링 팀과 엔지니어링 리더십 팀에게 이관했습니다.
런던의 엔지니어링 팀은 당시 진행 중이던 내부 기술 컨퍼런스를 즉시 중단하고 큰 컨퍼런스 룸에 모여서 이 문제를 논의하기 시작했습니다. 이 문제는 SRE 팀에서 단독으로 해결할 수 없는 문제였기 때문에, 관계된 사람들이 모두 온라인으로 모여서 논의를 해야 했습니다.
14시 00분에 이 문제의 원인이 외부의 공격이 아닌 WAF 때문이라는 것이 확인되었습니다. 퍼포먼스 팀에서 CPU 데이터를 추출하여 WAF에서 문제가 발생했다는 사실을 확인했고, 다른 팀에서 strace를 사용하여 이를 검증했습니다. 또 다른 팀은 에러 로그를 분석하여 WAF에서 문제가 발생했다는 사실을 재차 확인했습니다. 14시 02분에는 전세계의 WAF를 중단하는 “global kill” 기능을 사용하자는 결론에 도달했습니다.
하지만 global WAF kill을 사용하는 과정에는 또 다른 문제들이 있었습니다. 우리는 Access를 사용하여 내부 컨트롤 패널 접근을 관리하는데, 이 서비스가 같이 다운되어서 내부 컨트롤 패널에 접근이 불가능해진 것이었죠. (그리고 이를 복구한 후에는, 내부 컨트롤 패널에 자주 접속하지 않을 경우 권한을 제거하는 보안 기능 때문에, 일부 팀 멤버들의 접근 권한이 없어졌다는 사실도 깨달았습니다.)
또한 다른 Jira와 같은 내부 서비스나 빌드 시스템에도 접근이 불가능한 상태였습니다. 이러한 서비스에 접근하기 위해서는 우회 메커니즘을 사용해야 했는데, 이는 자주 사용하지 않아 익숙하지 않은 방식이었죠. 결과적으로, 팀 멤버 중 하나가 14시 07분에 global WAF kill을 실행시켰고, 14시 09분에 모든 트래픽 수준과 CPU 사용률이 정상 상태로 돌아왔습니다. WAF를 제외한 Cloudflare의 나머지 기능은 모두 정상적으로 작동하는 상태로 말이죠.
이어서 우리는 WAF 기능을 복구하는 작업에 착수했습니다. 이는 매우 중요한 사안이었기 때문에, 우리는 각 도시 별로 유료 고객의 트래픽을 제외한 일부 트래픽에 대해서, 네거티브 테스팅 (정말로 WAF 관리 규칙 때문에 문제가 발생한 것이 맞는가?)과 포지티브 테스팅 (롤백을 통해서 문제가 해결되었는가)을 수행했습니다.
14시 52분에 우리는 이 문제를 100% 이해했다는 것을 확신했고, 수정한 WAF를 다시 전 세계에 활성화했습니다.
Cloudflare의 동작 방식
Cloudflare에는 WAF 관리 규칙을 설정하는 엔지니어 팀이 있고, 이들은 지속적으로 탐지율을 개선하고 새로운 위협에 대응하기 위하여 노력합니다. 지난 60일간, WAF 관리 규칙 업데이트와 관련하여 476개의 Change Request가 발생했습니다 (평균 3시간 당 1번).
각각의 Change Request는 “시뮬레이션” 모드에 먼저 배포됩니다. 시뮬레이션 모드에서는 업데이트된 규칙이 실제 고객의 트래픽을 검사하지만, 블로킹(blocking)은 수행하지 않습니다. Cloudflare는 이를 통해 규칙의 효율성과 false positive, false negative 정도를 측정합니다. 하지만 시뮬레이션 모드에서도 모든 규칙은 실제로 실행되기 때문에, 잘못된 정규표현식을 사용한 규칙이 어마어마하게 CPU를 사용하는 사태가 발생했습니다.
위의 Change Request를 보면, 배포 계획(deployment plan)과 롤백 계획(rollback plan), 그리고 내부 SOP(Standard Operating Procedure) 링크를 확인할 수 있습니다. SOP는 변화된 규칙이 전세계로 배포될 수 있게 합니다. 이는 Cloudflare가 릴리즈하는 다른 모든 소프트웨어들과는 전혀 다른 방식입니다. Cloudflare에서는 원래 SOP가 소프트웨어를 내부 도그푸딩(dogfooding) 네트워크 PoP에만 배포하여 직원들이 우선적으로 테스트하게 합니다. 그 이후, 적은 수의 고객들이 사용하게끔 하고, 이후 더 많은 고객들, 최종적으로 전 세계에 소프트웨어를 배포합니다.
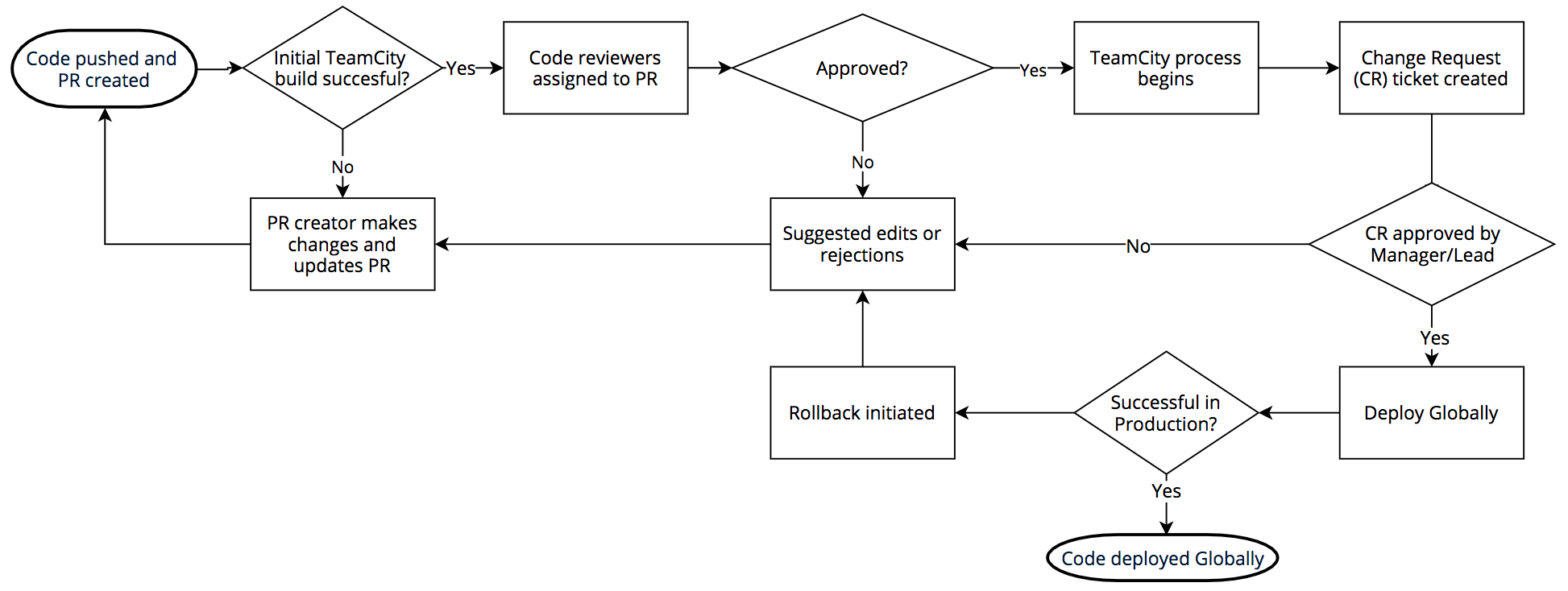
소프트웨어 릴리즈 과정은 다음과 같습니다. 우리는 BitBucket을 통한 git을 사용합니다. 엔지니어들이 코드를 푸시하면, TeamCity가 이를 빌드하고 빌드에 성공하면 리뷰어들이 코드를 리뷰합니다. 풀 리퀘스트가 통과(approve)되면 다시 코드를 빌드하고 테스트를 수행합니다.
빌드와 테스트가 모두 성공하면 Jira에 Change Request가 생성되고, 이는 해당하는 팀의 관리자 또는 팀 리더가 재차 검증합니다. 검증이 완료되면 우리가 “동물 PoPs"라고 부르는 DOG, PIG, 그리고 카나리아가 등장합니다.
DOG Pop은 Cloudflare의 직원들로만 구성된 Cloudflare PoP입니다. 이 도그푸딩 PoP는 고객들이 사용하기 전에 직원들이 문제를 발견할 수 있도록 해줍니다.
DOG 테스트에 통과하면 코드는 PIG PoP로 넘어갑니다. 이는 일부 무료 고객들로 구성된 Cloudflare PoP입니다.
PIG 테스트에서 통과한 코드는 카나리아로 넘어갑니다. 카나리아 PoP는 전 세계의 유무료 고객들로 구성되어 있고, 실제 배포하기 전 마지막 체크를 수행하는 단계입니다.
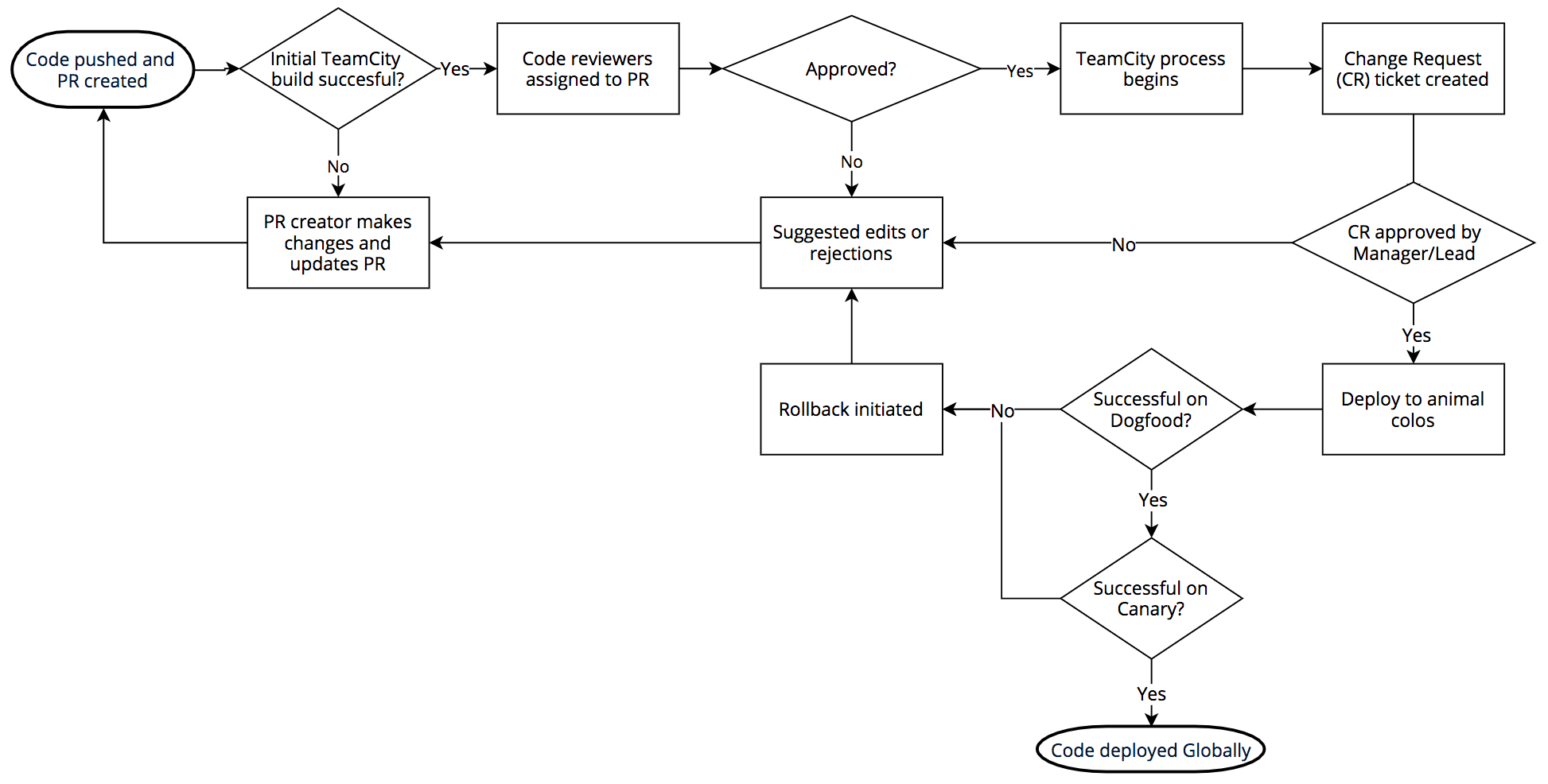
카나리아 테스트까지 통과한 코드만이 실제로 배포됩니다. DOG, PIG, 카나리아, 그리고 전세계에 배포하는 과정은 코드의 특성에 따라 몇시간 또는 며칠에 걸려서 이루어집니다.
그러나 WAF는 위협에 대한 신속한 대응이 매우 중요하기에, 이러한 단계적 배포 과정을 거치지 않습니다.
WAF와 보안 위협
최근 몇년간 일반 애플리케이션에서 발생하는 취약점의 수가 폭발적으로 증가했습니다. 이는 퍼징(fuzzing)과 같은 소프트웨어 테스트 툴의 사용이 증가하면서 발생한 결과입니다. (며칠 전 퍼징에 대한 글을 작성한 바가 있습니다.)
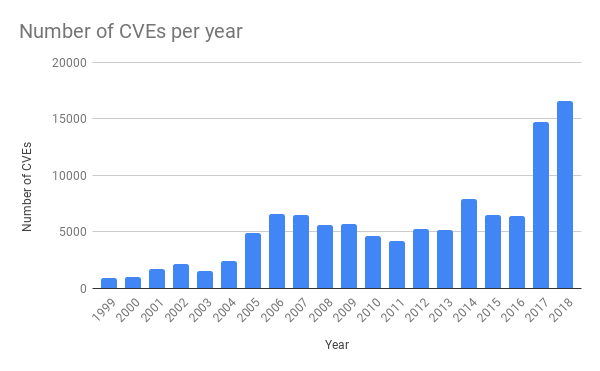
취약점에 대한 PoC(Proof of Concept)도 곧바로 깃헙에 공개되는 경우가 많고, 이를 통해 쉽게 취약점에 대한 적절한 방어체계가 갖추어져 있는지 확인할 수 있게 되었습니다. 따라서 새로운 공격에 대해서 최대한 빠르게 반응하여, 고객들이 패치된 소프트웨어를 사용할 수 있게 하는 것은 Cloudflare에 요구되는 아주 중요한 사안입니다.
지난 화요일의 장애 사태를 촉발한 규칙은 XSS(Cross-site Scripting) 공격을 대상으로 하는 것이었습니다. 이는 최근 드라마틱하게 늘어나고 있는 공격 방식 중 하나입니다.
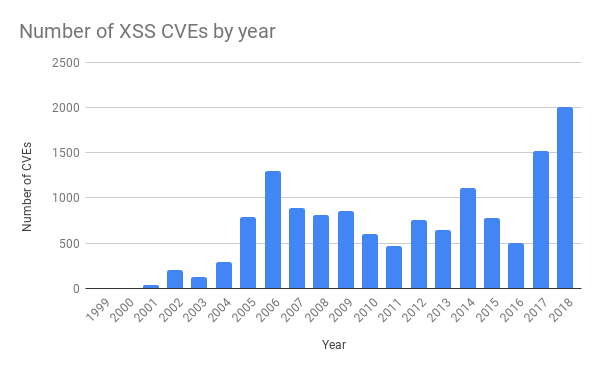
WAF 관리 규칙이 바뀌면 CI(Continuous Integration) 테스트가 먼저 수행되고, 이 테스트를 통과해야만 배포가 이루어집니다. 13시 31분에 방화벽 팀의 엔지니어가 풀 리퀘스트를 머지했습니다. 13시 37분에 TeamCity가 규칙을 빌드하고 테스트를 수행했습니다. WAF 테스트에서는 각 규칙에 대해서 수많은 HTTP 리퀘스트를 발생시켜 WAF가 제대로 방화벽 역할을 수행하는지 확인합니다. 그러나 WAF의 CPU 사용량을 검사하는 테스트나, 지난 테스트와 대비하여 얼마나 더 많은 시간이 소모되었는지를 검사하는 테스트는 존재하지 않았고, 이 때문에 테스트 과정에서 CPU 고갈 문제를 잡아내지 못했습니다.
테스트를 통과한 후, TeamCity는 13시 42분에 새로운 규칙을 배포했습니다.
Quicksilver
WAF 규칙들은 갑작스럽고 새로운 위협에 빠르게 대응하여야 하므로, Cloudflare의 자체 분산 key-value 스토어인 Quicksilver를 통하여 배포가 이루어집니다. Quicksilver는 업데이트가 발생할 경우 이를 몇 초 안에 전세계에 반영할 수 있도록 만들어졌습니다. 이 기술은 고객들이 Cloudflare 대시보드나 API를 사용하여 설정을 변경하는 경우에도 사용되며, Cloudflare의 서비스가 매우 빠르고 신속하게 반응할 수 있도록 하는 근간이 되는 기술입니다.
우리는 아직 Quicksilver에 대한 많은 정보를 공개한 적은 없습니다. 기존에는 글로벌 key-value 스토어로 Kyoto Tycoon을 사용하였으나, 운영상에 여러 이슈가 발생하였기 때문에 자체적으로 key-value 스토어를 구현하였고, 현재 180개가 넘는 도시에 동일한 Quicksilver 스토어가 존재합니다. 고객들의 설정 변경이 반영되고, WAF 규칙을 업데이트하고, Cloudflare Workers를 사용하는 고객들의 자바스크립트 코드를 배포하는 데에 모두 Quicksilver가 사용됩니다.
Quicksilver는 매우 빠릅니다. 평균적으로 2.29초만에 전 세계에 있는 모든 머신에 변화가 반영됩니다. 일반적으로, 속도가 빠르다는 것은 큰 장점입니다. 특정한 기능을 활성화하거나, 캐시를 초기화하는 경우 이것이 즉각적으로 전 세계에 반영될 것이라는 점에서 말입니다.
그러나, 본 사태에서는 Quicksilver의 빠른 속도란 곧 변경된 WAF 규칙이 몇 초만에 전 세계에 반영될 것임을 의미했습니다. 눈썰미가 좋은 분들은 우리의 WAF 코드가 Lua로 되어있음을 눈치채셨을 것입니다. Cloudflare는 Lua를 다양한 곳에서 사용하고 있는데 이에 대한 내용은 WAF와 Lua 포스트와 여기에서 논의된 바가 있습니다. Lua WAF는 내부적으로 PCRE를 사용하고, PCRE에서는 백트래킹 방식을 통해 문자열의 매칭 여부를 판단하는데, 이 때 정규표현식의 시간복잡도를 분석하여 제한하는 메커니즘이 PCRE에는 존재하지 않습니다.
따라서 새로운 WAF 규칙이 배포되기까지의 모든 과정에서는 잘못된 것이 없었습니다. 풀 리퀘스트가 발생하고, 리뷰어가 승인하였으며, CI가 코드를 빌드하고 테스트하며, Change Request가 SOP에 제출되고, 배포가 이루어졌습니다.
무엇이 잘못되었는가
앞서 언급한 것처럼, 우리는 매주 수십 개의 새로운 WAF 규칙을 배포하고 있고, 이러한 배포가 잘못된 영향을 주는 것을 막기 위한 여러 개의 시스템 또한 구축하고 있습니다. 따라서 문제는 주로 여러 원인들이 복합적으로 얽혀서 발생합니다. 단 하나의 주요 원인을 이야기하는 것은, 명쾌하긴 하지만 현실을 왜곡할 수 있습니다. 아래는 Cloudflare의 HTTP/HTTPS 서비스 장애를 야기한 복합적인 문제들을 나열한 것입니다.
- 한 엔지니어가 수많은 백트래킹이 발생하는 정규표현식을 작성함
- 정규표현식이 CPU를 과도하게 사용하는 것을 방지하는 방어 메커니즘이 WAF 리팩토링 과정에서 꺼져있었음
- 정규표현식 엔진이 시간복잡도를 확인하지 않음
- 테스트 과정에서 CPU 사용량을 확인하지 않음
- SOP가 새로운 WAF 규칙이 여러 단계를 거치지 않고 곧바로 전세계에 배포되도록 구성되어 있었음
- 롤백 과정이 WAF를 새로 두 번 빌드해야하여 너무 오래 걸림
- 글로벌 트래픽 드랍 경고가 매우 늦게 발생함
- 우리가 Cloudflare status 페이지를 빠르게 업데이트하지 않음
- 서비스 장애와 익숙하지 않은 절차 때문에 내부 시스템에 접근하는 데에 애로사항이 발생함
- 일부 SRE 팀원들이 자체 보안 기능으로 인하여 내부 시스템 접근 권한을 잃음
- Cloudflare 대시보드와 API가 Cloudflare 엣지를 거치게 되어있어서 고객들이 이를 사용하지 못함
사태 이후에 이루어진 일들
우리는 이 사태 이후 WAF의 릴리즈를 모두 멈추고 아래의 일을 수행하고 있습니다.
- 과도한 CPU 사용을 막는 메커니즘을 재활성화 (완료)
- 3868개의 WAF 관리 규칙을 모두 수동으로 검사하고 백트래킹이 과도하게 발생할 수 있는 정규표현식을 수정 (검사 완료)
- 각 규칙에 대한 퍼포먼스 측정을 테스트에 추가 (ETA: 7월 19일)
- 정규표현식 엔진을 런타임이 보장되는 re2 또는 Rust regex engine 으로 변경 (ETA: 7월 31일)
- 다른 Cloudflare 소프트웨어와 동일하게 WAF 배포 방식을 여러 단계를 거치도록 변경, 그러나 비상사태에는 빠르게 배포할 수 있도록 함
- 비상상황에서 Cloudflare 대시보드와 API가 Cloudflare 엣지를 거치지 않고 동작할 수 있도록 함
- Cloudflare Status 페이지가 자동 업데이트 되도록 함
또한 장기적으로는 Lua로 작성된 WAF에서 벗어나, 새로운 방화벽 엔진으로 WAF를 포팅할 계획입니다. 이는 WAF가 더 빠르게 동작하도록 만들어줄 것입니다.
Reference
https://blog.cloudflare.com/details-of-the-cloudflare-outage-on-july-2-2019/
Author ryanking13
LastMod 2019-07-18