그누보드 캡차 인식 프로젝트 - Part 1
Contents
그누보드에서 사용하는 오픈소스 캡차 프로그램인 KCAPTCHA를 인식하는 머신러닝 토이 프로젝트 개발 내용에 대한 글입니다.
이런 내용에 대해 다룹니다
- 데이터 수집 - 모델 구현 - 학습 - 모델 배포 파이프라인
- 개발 과정에서 발생한 이슈와 해결책
이런 내용을 다루지 않습니다
- 텐서플로우 기초 문법
- 최신 머신러닝 모델 및 학습 기법
들어가며
그누보드는 한국의 웹사이트에 널리 사용되는 대표적인 설치형 인터넷 게시판 소프트웨어(CMS, Contents Management System)입니다.
그누보드는 스팸 게시글이 등록되는 것을 방지하기 위해 러시아에서 개발된 KCAPTCHA 캡차 프로그램을 사용합니다.1


KCAPTCHA는 마지막으로 업데이트 된 것이 2011년도인 굉장히 고전적인 캡차인데요.
최근의 캡차 트렌드가 머신러닝 기반 OCR 공격을 피하기 위해 글자 방식에서 벗어나거나2, 역으로 머신러닝을 활용해서 강인한 캡차를 만드는 것임을 고려하면, KCAPTCHA는 상당히 쉬운 캡차라고 할 수 있습니다. 그래서인지 일반 OCR API를 사용해서 KCAPTCHA를 파훼하려 한 시도도 있었구요.
그래서 KCAPTCHA를 타겟으로 학습된 머신러닝 모델로는 어느 정도 인식 성능을 낼 수 있을까하는 궁금증에 (그리고 심심해서)
이 토이 프로젝트를 시작했습니다.
프로젝트의 목표는 다음과 같습니다.
- 길이 2의 숫자로 구성된 KCAPTCHA에 대해 95% 이상의 성능을 내는 모델 학습
- 학습한 모델을 자바스크립트로 변환하여 브라우저 환경에 배포
프로젝트의 목표가 아닌 것은 다음과 같습니다.
- 다른 종류의 캡차에 일반화될 수 있는 캡차 인식 모델 학습
프로젝트를 진행한 머신의 환경 및 스펙은 다음과 같습니다.
- OS: Windows10 x64
- GPU: NVIDIA RTX 3070
- Tools: Tensorflow 2.4.0 / CUDA 11.0
⚒️ 개발 프레임워크 선정
개발을 시작하기 전 가장 먼저 한 일은 Tensorflow와 PyTorch 중 어떤 프레임워크를 사용할 지를 결정하는 것이었습니다. 저는 PyTorch를 선호하는 편이지만, 이 프로젝트의 최종 목표가 학습된 모델을 외부에 배포하는 데에 있다는 점을 고려하여야 합니다.
모델 배포를 위해 GPU가 달린 클라우드 서버를 운용하는 것은 비용적으로 부담이 되기 때문에, 파이썬으로 학습한 모델을 자바스크립트로 변환하여 서버 없이 브라우저 환경에 배포하는 것을 목표로 잡았습니다. 머신러닝 모델의 자바스크립트 변환을 지원하는 라이브러리는 Tensorflow.js밖에 없으므로, 개발 도구는 Tensorflow로 자연스럽게 정해졌습니다.
Note: 사실 Pytorch 모델을 ONNX로 변환한 뒤 onnx.js를 사용해서 자바스크립트로 변환하는 방법도 있습니다. 프로젝트를 진행할 당시에는 이 방법을 알지 못했습니다.
💾 데이터 수집
다음으로는 데이터가 없으면 아무 것도 할 수 없으므로 학습에 사용할 데이터를 수집하였습니다.
제일 확실한 데이터 수집 방법은 실제 KCAPTCHA 프로그램을 운용 중인 다양한 그누보드 웹사이트에서 캡차 이미지를 수집하는 것이겠지만, 이는 법적 문제 소지가 있으므로, 직접 데이터를 생성하기로 하였습니다.
다행히 PHP로 만들어진 KCAPTCHA는 오픈소스로 공개되어 있으므로 누구나 다운로드 받아 사용할 수 있으며, 또한 그누보드도 오픈소스이므로 그누보드에서 KCAPTCHA에 사용하는 디폴트 옵션도 똑같이 적용할 수 있습니다.
| |
먼저 PHP로 작성된 KCAPTCHA 소스코드를 수정하여, 원하는 캡차 문자열 이미지를 생성할 수 있도록 하고,
| |
캡차 이미지 생성을 자동화하는 파이썬 스크립트를 작성하여 수만장의 캡차 이미지를 생성하였습니다.
전체 데이터셋 생성 코드는 여기서 볼 수 있습니다.
📜 문제 정의
이제 데이터를 다 모았으니 모델을 만들어서 돌리면 끝…! 이라고 하고 싶지만, 그전에 우리가 풀고자 하는 문제가 대체 무엇이며, 이를 어떻게 데이터로 표현할 지 정의할 필요가 있습니다.
문제 정의
먼저 캡차를 푼다라는 과제(task)를 다음과 같이 정의하겠습니다.
C개의 클래스로 구성된 길이의L의 문자열을 분류(classify)하는 과제
C는 캡차를 구성하는 것이 숫자(0-9)인지, 알파벳(a-z)인지 등을 나타내고, L은 캡차의 길이를 나타냅니다.
이 글에서는 기본적으로 숫자(0-9)만으로 구성된 길이 2의 캡차를 푸는 문제를 다루도록 하겠습니다. (C=10, L=2)
데이터 임베딩
다음으로는 이 문제에 맞게끔 데이터(label)를 어떻게 임베딩할지 정합니다. 일반적으로 생각할 수 있는 분류기의 출력은 크게 다음의 두 가지입니다.
- C 길이의 1차원 벡터 L개
- C * L 길이의 1차원 벡터 1개
전자는 MNIST 문제가 L개 있는 것이라고 생각할 수 있겠습니다(단, 입력 이미지는 한 개이지만요). 이 경우 모델의 전체 loss는 L개의 출력에 대해 각각의 loss를 더한 값으로 정의할 수 있습니다.
예를 들어 숫자 42는 다음과 같이 임베딩됩니다.
| |
한편, 후자는 전자의 출력을 하나의 벡터에 모두 이어붙인 형태입니다. 출력이 하나이므로 모델의 loss는 해당 출력의 loss만 계산하면 됩니다.
후자의 경우 숫자 42는 다음과 같이 임베딩됩니다.
| |
둘 중 어느 방식을 사용하느냐는 선택하기 나름이겠습니다만, 저는 전자의 경우 multi-output이 구현 측면에서 번거로운 점이 있을 것이라고 판단해, 후자의 방식을 채택했습니다.
| |
파이썬으로 구현한 데이터 임베딩 코드는 위와 같습니다.
loss 함수 정의
| |
데이터 임베딩을 정한 것까지는 좋은데, loss 함수는 어떻게 정의해야 할까요?
MNIST와 같이 데이터를 C개의 클래스 중 하나의 클래스로 분류하는 Multi-class classfication 문제는
모델의 출력에 Softmax 함수를 붙여서 전체 출력의 합을 1로 만들고
Cross Entropy 함수를 loss 함수로 사용하면 됩니다.
그런데 여기서는 전체 벡터의 합이 1이 아닌 길이 L(위 경우는 2)이므로 뭔가 딱 들어맞지 않아 보입니다.
이 문제는 하나의 데이터가 여러 개의 클래스(십의 자리 숫자와 일의 자리 숫자)를 가지는 문제로,
Multi-Label classification에 속한다고 보는 것이 적합해 보이는데요. Multi-Label classification 문제의 loss 함수를 정의하는 방법 중 가장 간단한 것은 Binary Cross Entropy를 사용하는 것입니다. C * L개의 출력을 각각 독립적인 이진 분류 결과로 취급하는 것입니다 (참고).
그 외에도 Soft-F1 Loss 등의 다른 loss 함수를 사용하는 방법도 있지만, 편의상 여기서는 Binary Cross Entropy 함수를 사용하도록 하겠습니다.
추가: 사실 이 문제는 캡차의 길이가 고정된(1인 label의 개수가 정해진) 특수한 케이스이므로 Cross Entropy를 잘 써서 loss를 정의하는 것도 충분히 가능하다고 생각됩니다.
👨💻 모델 선정 / 학습 구현
이제 실제로 학습 파이프라인을 구현할 차례입니다.
모델은 Keras에서 공식적으로 지원하는 모델을 사용했습니다. Keras는 다양한 모델을 지원하지만, 최종 브라우저 배포 환경을 고려하여 파라미터 수가 많지 않은(용량이 작은) 아래의 모델들을 선정했습니다.
- MobileNetV2 (16MB)
- DenseNet121 (33MB)
- EfficientNetB0 (29MB)
| |
ImageNet으로 사전 학습된 모델을 사용했습니다. 작은 프로젝트에서는 Keras를 쓰면 구현이 참 편리합니다. 😏
| |
| |
학습 과정도 Keras API를 활용하여 간단히 구현하였습니다.
| |
한 가지 포인트가 되는 부분은, 모델의 출력이 일반적인 문제와 다르기 때문에, 모델의 정확도를 측정하는 커스텀 metric을 작성하여 넣어주었습니다.
전체 학습 코드는 여기에서 볼 수 있습니다.
📉 학습 결과
각 모델별 학습 결과는 다음과 같습니다.
총 10000장의 캡차 이미지로 구성된 데이터셋을 사용했고, 학습에 6401장, 검증에 1599장, 테스트에 2000장을 사용했습니다.
| Model | Train Accuracy | Test Accuracy |
|---|---|---|
| MobilenetV2 | 98.6% | 25.7% |
| Densenet121 | 99.9% | 99.6% |
| EfficientnetB0 | 99.3% | 99.2% |
MobileNetV2는 완전히 학습 데이터셋에 오버피팅 된 결과를 보입니다. 학습 정확도가 98%를 넘은 반면, 테스트 정확도는 25%에 불과했네요.
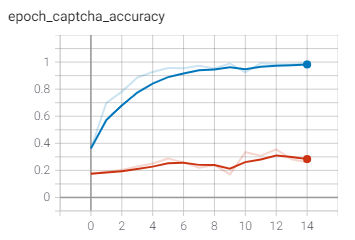
학습 곡선으로 봐도 테스트 정확도가 학습 정확도를 전혀 따라가지 못하는 모습을 보이네요.
그에 비해 Densenet121과 EfficientnetB0는 학습 정확도와 테스트 정확도 모두 99% 수준의 만족스러운 결과를 보입니다.
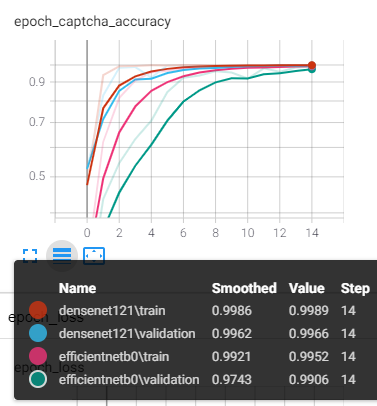
다만 학습 곡선으로 보면 두 모델의 차이를 느낄 수 있는데, Densenet121이 학습 정확도와 테스트 정확도 모두 굉장히 빠르게 수렴하는 모습을 보이는 것에 비해, EfficientnetB0는 학습 정확도가 천천히 수렴하고, 테스트 정확도는 더욱 천천히 수렴하는 모습을 확인할 수 있습니다.
잘 학습된 모델을 만드는데 성공했으니, 이제 다음은 모델을 배포할 차례입니다.
🚢 모델 배포
이어지는 글에서는 학습한 모델을 Tensorflow.js로 변환하여 배포하는 과정에 대해서 살펴보도록 하겠습니다.
✅ 개선 가능한 부분들
처음 목표한 대로 길이 2의 숫자 캡차에 대해 95% 이상의 정확도를 보이는 모델을 만들었지만, 사실 이 글에서는 굉장히 쉬운 상황을 가정하였기 때문에 현실 세계에 적용하기 위해서는 다양한 개선이 필요합니다.
- 노이즈에 강인한 모델
KCAPTCHA 캡차 이미지 생성 시에, 생성 옵션을 살짝 조정하는 것으로, 여러 가지 노이즈가 추가된 데이터를 생성할 수 있습니다. 이 경우 학습 데이터와 테스트 데이터의 분포가 달라지게 되므로 기존의 학습 데이터로 학습한 모델의 성능이 저하될텐데요.
노이즈에 강인한 모델을 만들기 위해서는 크게 아래와 같은 방법을 사용할 수 있습니다.
- 다양한 노이즈가 추가된 데이터를 학습 과정에 포함시키기
- 적절한 데이터 증강(Augmentation) 기법 활용
- 가변 길이 캡차
이 글에서는 캡차의 길이가 정해져 있다고 가정했는데, 사실 현실에서는 대부분 가변적인 길이의 캡차를 사용합니다.
가변 길이 캡차를 풀기 위해서 시도해볼 수 있는 방법으로는 크게 두 가지가 있을 것 같습니다.
- Classfication 모델이 아닌 Object Detection 모델 활용
- Two Stage Classfication: 캡차 길이를 탐지 모델 + 정해진 길이의 캡차를 푸는 모델
Links
Author ryanking13
LastMod 2021-02-01